
このページは2021 年 11 月 12 日 14:25〜15:55に神戸市外国語大学で実施したワークショップの資料と録画を公開しているページです。中国語の検索について知りたい方はまずこちらをご覧ください。
ワークショップの内容
次のようなことができるようになるきっかけ作りをします。
- 卓球、野球、サッカー… 検索結果から見る中国の真の国民的スポーツは○○ ―Google Trend検索
- ウェブで中国語を効率的に検索する―Google演算子検索
- 繁体字サイトと簡体字サイトの情報の比較する―Google地域・言語限定検索
- 政府系サイトに限定して中国語文書を検索する―Googleドメイン検索
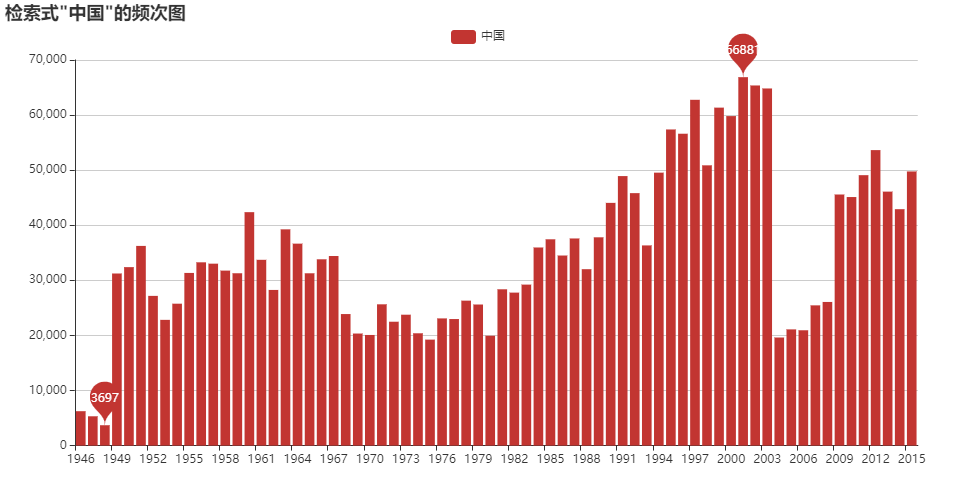
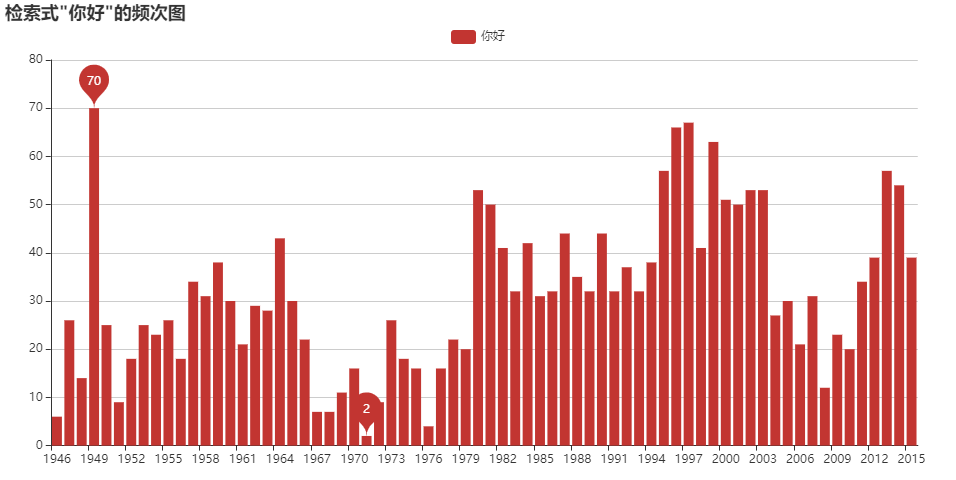
- “你好”が使われ出したのは○○から―公開型コーパスを使った歴史検索
- ウェブで集めたデータから情報を抽出―正規表現を使った検索
Google Trendで検索のトレンドをおっかける
2004年から現在までの「世界中の検索トレンド」をチェックするためのツール、入力した単語の検索数を表示する、複数の単語を入力するとそれぞれの単語の検索数を相対化して比較、表示します。国、地域によって絞り込むことが可能で、中国語では、「中国・香港・台湾」を分けて調べることができます。
- “乒乓球 羽毛球 足球 棒球”をそれぞれ「2004-現在」「中国」という上限に限定して検索してみましょう。それぞれどこでよく検索されているか、検索数が増えるタイミングを確認してみましょう。
- 4つのキーワードを比較してみましょう。どのスポーツが一番よく検索されていますか?
- 一番人気があるスポーツを消してみましょう。次によく検索されているのは?
- 「タイガース」「ジャイアンツ」「イーグルス」「マリーンズ」「カープ」「ホークス」「ファイターズ」…どの地域に(熱狂的)ファンが多いか視覚化して確認してみましょう。
- 期間、対象するチームなどを変更して比較していき特徴をつかんでいきましょう。
- 咳、熱、下痢、風邪…を別々に検索してみましょう。
- 「咳」単独の検索結果を確認しつつ、「咳、コロナ」を比較検索してみましょう。
あるタイミングで「コロナ」という具体的な単語に検索キーワードがシフトしているタイミングがあることに気が付きましたか?
Google検索を使いこなす
限定検索機能・演算子検索
Googleは単にキーワードを広いインターネットの情報から検索するだけではなく、検索条件を絞り込んで検索することができます。
- 日中同形語「光彩,主席,首席,人工,人道,点滴,慢性,一口,基本」の中国語の用例を検索したい場合
- 中国・香港・台湾・日本それぞれの「ポスト」の画像を検索したい場合
- ピンイン、簡体字、日本の国字の取り扱いなどについて中国の政府系の公式文書を検索したい場合
- 簡体字サイト(主に中国大陸)と繁体字サイト(主に香港・台湾)で特定の期間に更新、発表されたページで「福原愛」がどのように書かれているか比較検討したい場合
- 携帯電話”手机”、コロナ”新冠”の量詞を知りたい場合
Googleオプション検索
Google検索は「オプション検索」(限定検索)で以下の点を選択して検索することができます。
右上の歯車マークから「検索オプション」を選択
- 地域…中国、香港、台湾…
- 言語…中国語(簡体)、中国語(繁体)…
- ドメイン…gov com ac…
- 最終更新日…24時間以内、1年以内…
- 検索対象の範囲…全体、ページタイトル、本文…
- ファイル形式…pdf ppt doc xls…
中国×簡体字×gov.cn=政府系文書
日本×簡体字=日本の簡体字サイト
「福原愛(”福原爱”)」の簡体字、繁体字サイトでの比較はもうできますね?
Google演算子検索
Googleは検索ボックスにキーワードを入れて検索した場合、単語単位に分割されAND検索された結果が返ってきます。試しに「中国国家主席」と検索して確認してみてください。「中国/国家/主席」という3つのキーワードに分割されます。
- 中国国家主席というキーワードのみ検索したい。
“”を使った「完全一致検索」を使う
例) “中国国家主席”
- 大陸で”主席”がどんな言葉とよく一緒に出て来るかを検索したい。
演算子検索を使って「マイナス検索」
検索結果からよく出て来る結果を「-」を使って除外していく
例)主席 -副 -中央军委 -中华人民共和国 -国家 -政协
- “手机”の量詞を検索したい
演算子検索を使って「*検索」
*を使って任意の文字検索
例)”两*手机” →两部手机 两台手机 两只手机 两个手机 两款手机 两张手机卡
“两”を組み合わせたのは他の数字に比べて後ろに量詞のみが来る可能性が高いから
そのほか「A AND B」形式のAND検索、「A OR B」形式のOR検索、Site:サイト名を使った「サイト限定検索」(例:)拼音 site:http://www.people.com.cn/ なども演算子を使った検索になります。これに言語や地域限定検索を併用するとさらに検索できる範囲を狭めることができます。
公開型コーパスを使用した検索
ネットで公開されているコーパスは多くありますが、収録しているデータの種類、時期、分量などをよく見たうえで使ってください。今回のワークショップではBCC語料庫を紹介します。
主なコーパス一覧
中国語を扱ったコーパス
- CCL(北京大学中国语言学研究中心)
- BCC (大数据与语言教育研究所)历时检索 …ワークショップではこれを紹介
- 现代汉语语料库检索(语料库在线)…国家语委现代汉语语料库
- HSK动态作文语料库…HSKの作文問題の解答コーパス
- LIVAC泛華語地區漢語共時語料庫…複数地点での語彙の仕様頻度
- CKIP Lab…台湾
- 現代漢語標記語料庫(中央研究院)
- A collection of Chinese corpora and frequency lists…リーズ大学(英)
日本語を扱ったコーパス
- 日本語コーパス(国立国語研究所)
BCC语料库
北京語言大学が運営、公開している中国語を対象としたコーパスで、新聞雑誌(20億字)、文学作品(30億字)、Weibo(30億字)、科学技術関係の記事(30億字)、総合(10億字)、古代中国語(20億字)の計150億字のデータが収録されいるコーパス。キーワード検索ができるだけではなく、統計機能、歴史検索、検索式を使った検索ができるので便利。文学、新聞雑誌、会話、古漢語などに分けて検索することもできます。
シンプルな検索
例)熊猫 你好 手机
検索結果から「絞り込み」…近くに「北京」が出現する文を抽出

検索結果から「北京」を除外
検索式を用いた検索
| 検索式サンプル | 意味 | 結果例 |
| 很多n | “很多” + 名詞 | 很多人,很多东西 |
| v一v | 动词+ 一 + 动词 | |
| 结*婚 | 結婚の間に任意の文字列 | 结了一次婚,结过好几次婚 |
| 结~婚 | | 结个婚,结错婚 |
| 结.婚 | | 结个婚,结错婚 |
| 结@婚 | | 结什么, 婚结个婚 |
| ./v | 1字の動詞(大量に出すぎて反応が返ってこない) | |
| ../v | 2字の動詞 | 学习,下雪,采用 |
| …/v | 3字の動詞 | 开玩笑,对不起 |
| 我 ./c 你 | 我と你の間に1字の接続詞が入る | 我和你,我或你 |
| v[下去 出来 上来 进去] | 動詞の後ろに[ ]内に入れた単語が続く | 说出来, 活下去 |
| [二 两] q n | "二"or"两“の後ろに量詞+名詞 | 两种速度,两个秘密 |
| [二 两] q手机 | "二"or"两“の後ろに量詞+ "手机" | 两个手机,两部手机 |
| 是*的 | "是…的"構文 | |
| (v)了又(v){$1=$2;len($1)=1} | 動詞+了又+動詞のフレーズで $1=$2 …$1と$2の内容が同じ len…長さの制限…len($1)=n…文字の長さは1字 最初のvは1文字 | 看了又看 |
| (v)了又(v){$1=$2;len($2)=2} | 動詞+了又+動詞のフレーズで $1=$2 …$1と$2の内容が同じ len…長さの制限…len($2)=n…文字の長さは2字 最初のvは2文字 | 研究了又研究,下雪了又下雪 |
| (v)一(v){$1=$2;len($1)=1} | V一V型の重ね型 | 哭一哭,飞一飞 |
統計機能
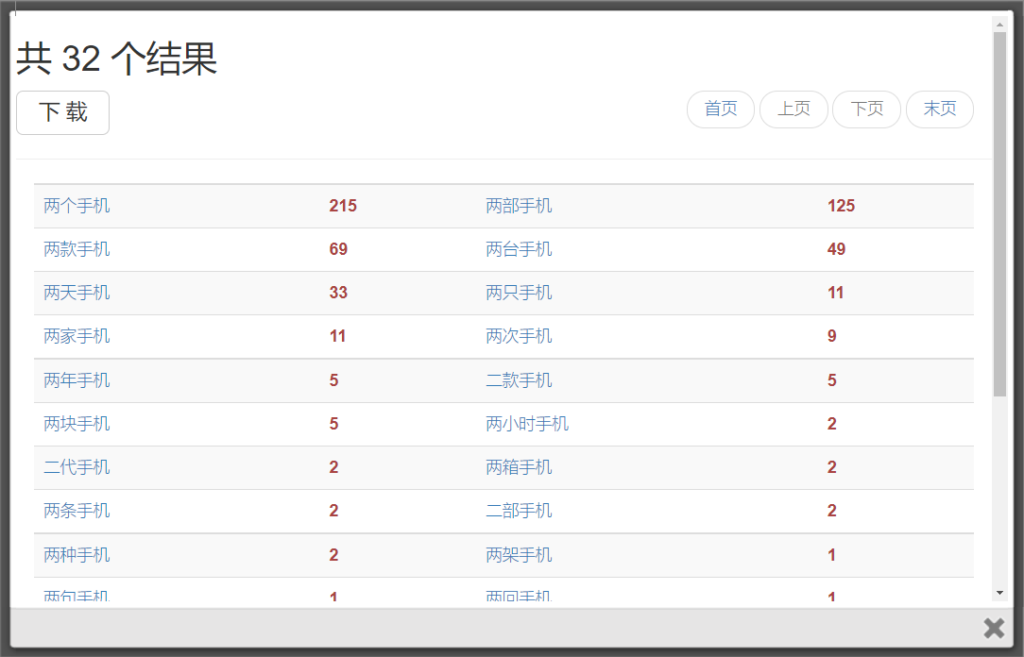
[二 两] q手机 +統計機能=? …手机にはどんな量詞がよく使われるか?
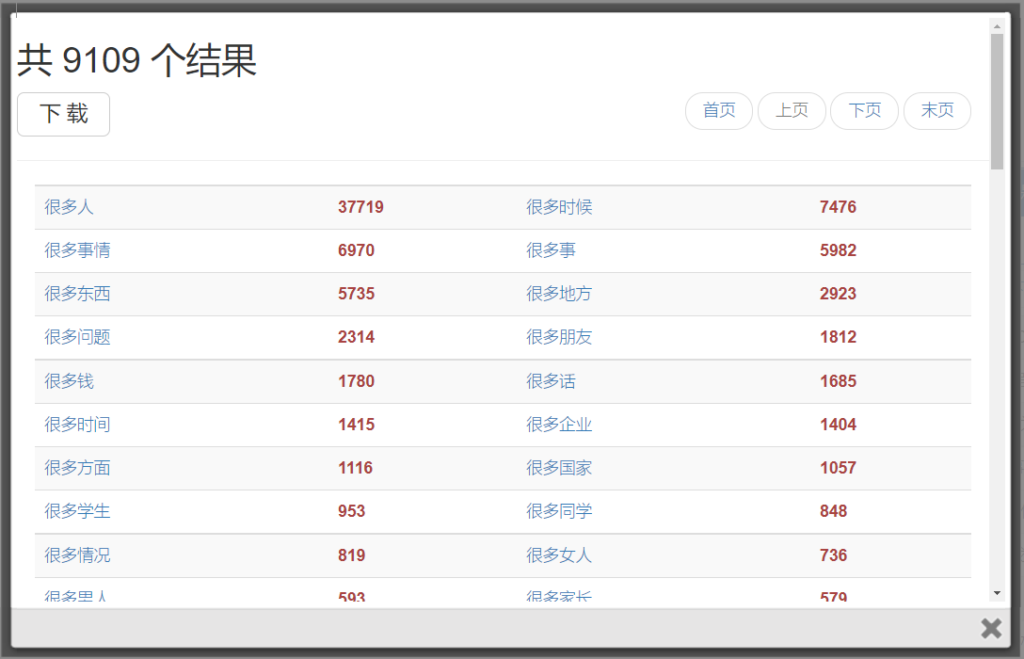
很多n +統計機能=?
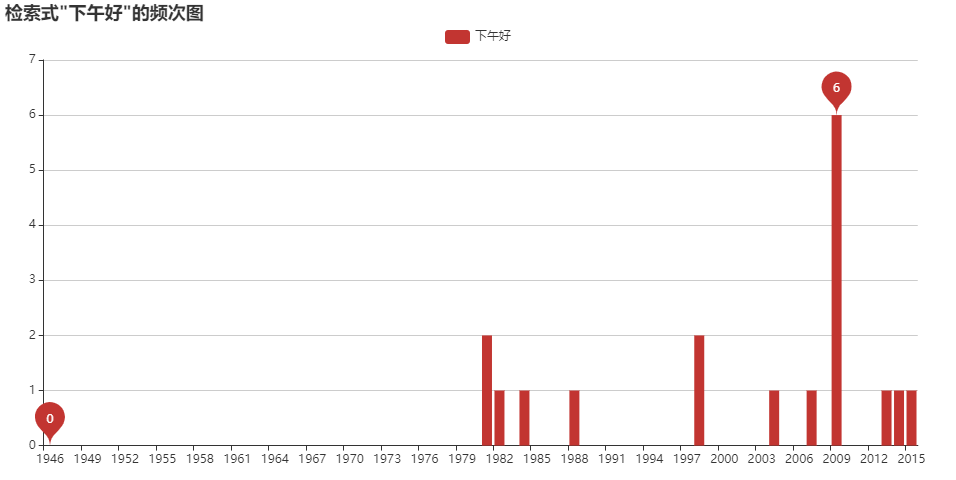
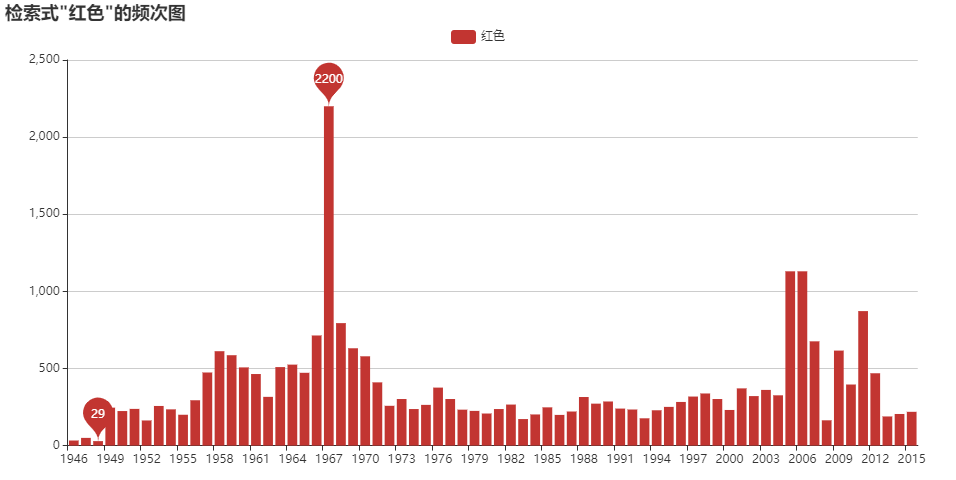
歴史検索

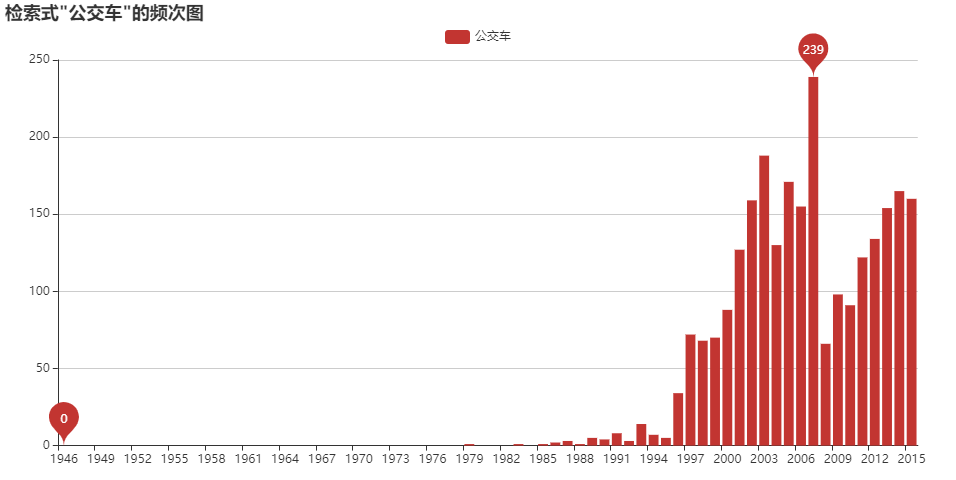
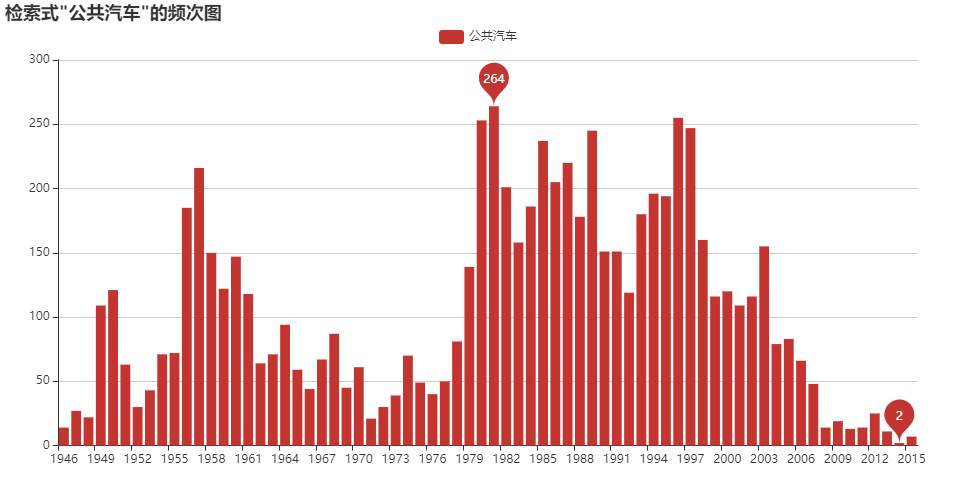
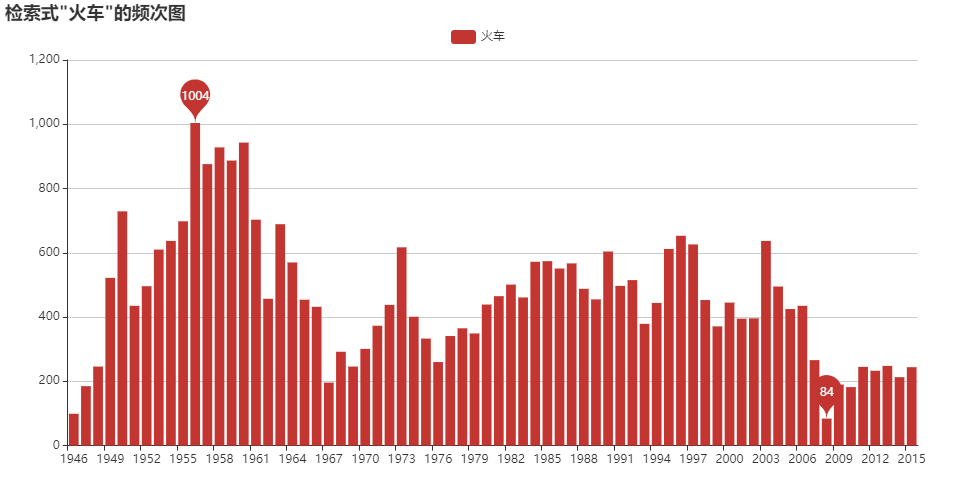
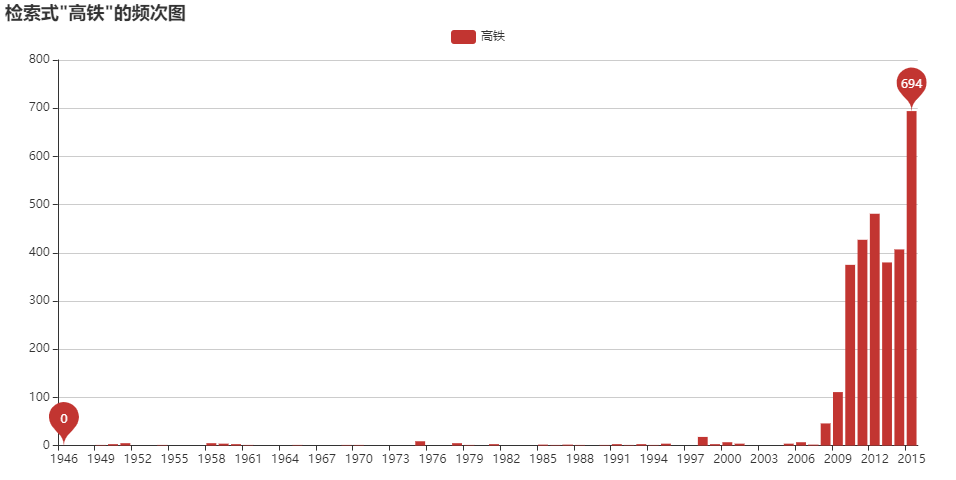
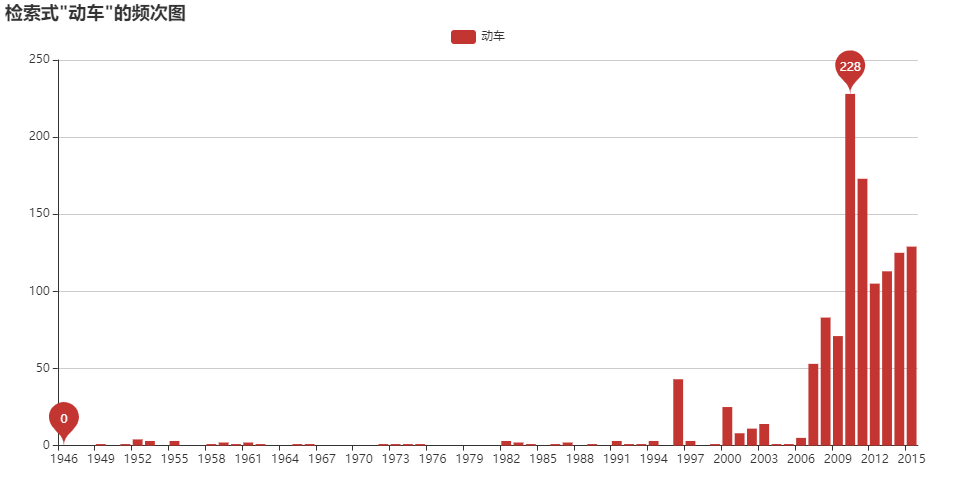
正規表現を用いたテキスト検索
インターネットや公開型コーパスにないデータを扱った研究を行いたい場合、自分でデータを作成して、簡易なコーパスを自身のPCに構築する必要があります。たとえば中国語の教材の本文データを扱った研究をしたい、日中の漫画のセリフの比較研究をしたい、中国のドラマのセリフを対象とした研究を行いたい…といった場合、公開されているデータはありませんね。こういった研究を遂行するためには①データを作成する、②検索するといった2段階の工程が必要となりますが、どのようにデータを作成し、整理する必要があるのか見ていきましょう。またこれまで見てきたような高度な検索を行うと良いのか考えてみましょう。
エディタを利用した検索と高度な検索を行うための「正規表現」
検索にはテキストエディタを使って検索します。使用するエディタエディタは、複数のファイルからGrep検索(ファイルの中で特定の文字列が含まれている行を表示する検索)ができ、正規表現が使え、多言語対応しているものであればなんでもかまいません。ATOMやEmEditor、秀丸エディタなどが有名ですが、すべての条件を兼ね備えて、無料で、Win/Macいずれでも使えるエディタとして本ワークショップではATOMで基本的な操作方法を学びましょう。Atomはデフォルトではメニューなどが英語表記されています。日本語化したい場合は、こちらの記事が参考になります。
データの収集・作成
検索対象とするデータの種類により集め方、作成方法は異なりますが、漫画・ドラマのセリフなどについては字幕(str形式のファイル)などがネット上に公開されていない限り基本的に人海戦術で入力していく以外方法はありません。ひたすら入力しましょう。
ネットに公開されているデータであれば「Website Explorer」などウェブサイトを一括して保存、ダウンロードできるようなアプリケーションを使ってPC上に保存、不要なタグや文字列を「マクロ」を使って一括して削除し、必要なデータを抽出、整形していく方法などが考えられます(今回はこの工程は説明しません)。
例)青空文庫の小説データ、人民日報の新聞データ、図書館などに眠る北京で収集されたインタビュー文字お越しデータ(北京口語資料)、Wikipediaをダウンロードしたデータ、Weiboのつぶやきやbilibiliの弾幕コメントデータ、漫画のセリフ(日中並列)データ、ドラマの文字お越しデータ(発話者の年齢や話している場面などをつけることも)など様々なデータを活用することもできます。
今回は準備した中国語のデータを使って検索の仕方やデータの保存の仕方を確認してみましょう。
サンプルデータのダウンロードと展開
- データをダウンロードしたら解凍して分かりやすい場所にフォルダを配置してください。
- Chinese-Dataという以下のフォルダが入っていることを確認してください。
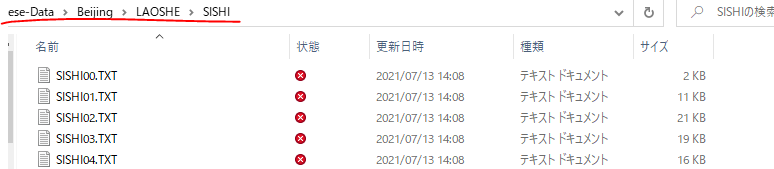
データの中身について
「Beijing(北京出身の小説家)」→「LAOSHE(老舎)」→「SiSHI(四世同堂)」とフォルダが階層化されており、「SISHI00.txt~67.txt」というテキストファイルが保存されています。たとえば 「SISHI01.txt」は 老舎の『 四世同堂 』の第一部というわけです。フォルダに細かく階層化しているのは検索範囲の視認性向上や検索対象の絞り込みをしやすくするためです。
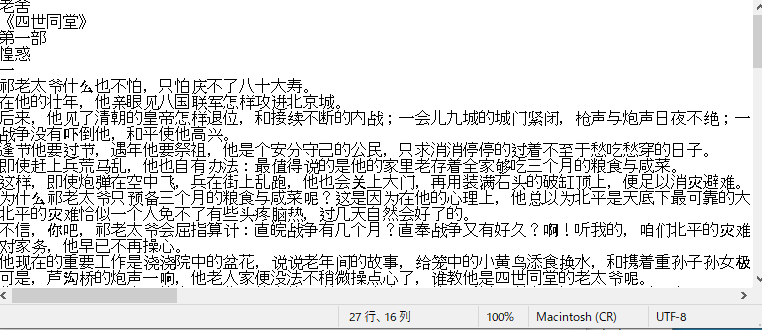
なおテキストファイルはすべて「UTF-8」というエンコードで保存されています。
「Chinese-Data」「Beijing」「chun-a」「CHUN01.TXT」のようにタグをつけたファイルを作ると品詞を関連付けた検索をすることもできます。簡易なタグ付けなら「语料库在线」を使用が便利。

テキストエディタを用いたGrep検索
Wordに保存された文書は、1ファイルずつ開いてそれぞれで検索しない、中身を検索することができませんが、テキストエディタを使ってテキストファイルを検索する場合は、複数のファイルを開かずに検索することができます。
ATOMを使った検索
- Atomを起動して、「ファイル」→「プロジェクトフォルダを追加」
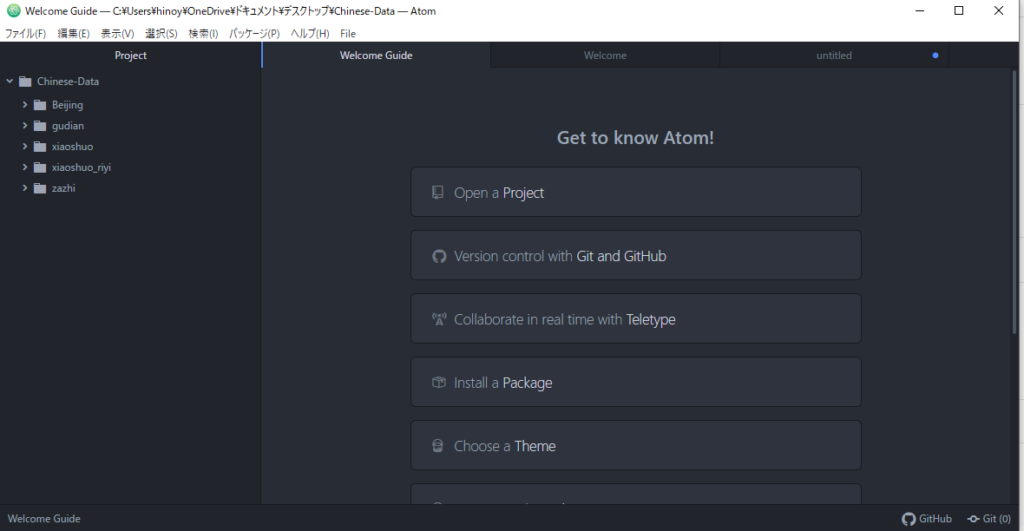
- 「検索」→「プロジェクト内検索」 “熊猫”を検索…Chinese-Dataフォルダ以下にある全てのファイルから”熊猫”を検索、結果は31のファイルの中に164個の”熊猫”発見。
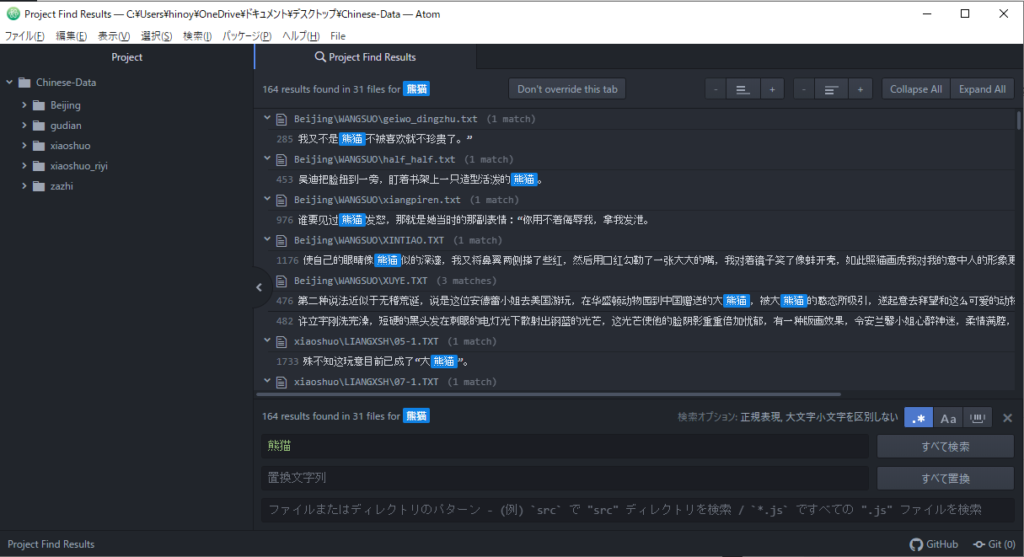
- 小説>三毛《背影》12-4に1件、雑誌>94年に61件ヒットしている。
- フォルダ=1作品としてテキストデータを整理して蓄積
- フォルダの構成は自分が研究したい内容や対象によりどう分類していくのが良いかを考える
- エンコード(文字コード)はUTF-8(Unicode)で保存する
- テキストは可能であれば1文1行の形式で保存する(データ抽出後後処理が必要)
- 正規表現の使い方が分かれば置換で小説の中からセリフデータだけを抜きだして保存することもできる
テキストエディタを用いた正規表現を使った高度な検索
正規表現を使うとGoogleの演算子検索や、公開型コーパスの検索式を用いた検索を再現することができます。またデータの後処理、整形作業も楽になります。Atomで正規表現を使う場合は、「.*」というボタンを押してください。
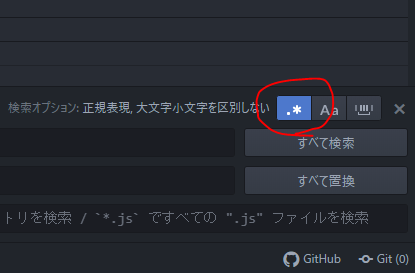
文書の整形に便利な正規表現
| 正規表現 | 意味 | 使用例 |
| \n | 改行 | [置換前]\n [置換後]\n\n [意味]空白行をつめる |
| ^\n | 空白行 | [置換前]^\n [置換後] [意味]空白行を削除 |
| \t | タブ | [置換前]\t [置換後]\x20 [意味]タブスペースを半角スペースに置換 |
| \x20 | 半角スペース | |
| \s | スペースすべて | |
| \S | 文字すべて | |
| \d | 半角数字すべて | \d{4}[/\.年]\d{1,2}[/\.月]\d{1,2}日? \d{4}[/\.年]\d{1,2}[/\.月]\d{1,2}号? |
| \D | 半角数字以外のすべて |
中国語の検索に便利な正規表現
| 正規表現の記号 | 意味 | 使用例 |
| ^(カラット) | ^は、文字列の先頭、行の先頭にマッチする。 ^ABCは、行頭にある ABCにマッチ | ^这是 |
| $ (ドル記号) | $は、文字列の終わり、行の終わりにマッチする。 ABC$は、行末にある ABCにマッチ | 回来。$ |
| .(ピリオド) | .は、改行コード (¥n) 以外の任意の 1文字にマッチする。 「…」なら任意の 3文字にマッチすることになる。 a.cは、 abc、ace、adc…などにマッチ | 这.是 结.婚 生..气 一.二. |
| * (アスタリスク) | *は、直前の 1文字(または正規表現)の 0回以上の繰り返しにマッチする (0回も含む)。 ab*cは、 ac、abc、abbc、abbbc、…のいずれかにマッチ 「.*」は、空文字列を含む任意の文字列にマッチ ただし「.*」は、‘‘結”と“婚”の間に挟まれている任意文字列が適合の条件になっているので、“…結果,婚礼没能按吋挙行。”のような例にもマッチしてしまう。 | 結.*婚 |
| +(プラス) | ⁺は、直前の 1文字(または正規表現)の 1回以上の繰り返しにマッチする (0回は含まない)。 ab+cは、 abc、abbc、abbbc、…のいずれかにマッチ (acにはマッチしない) 「.⁺」は、任意の文字列にマッチ 、 ”回来”にはマッチしない。 | 回.+来 |
| ? (疑問符) | ?は、直前の 1文字(もしくは正規表現)の 0回か 1回の出現を表す。?は、繰り返しのメタ文字といわれるが、実際は 2回以上の繰り返しはしない。 ab?cは、 ac、abcのいずれかにマッチ | 看ー?看” |
| | (選択) | |は文字列の選択を表す。 “あるいは |或いは”は、「あるいは」と「或いは」のどちらにもマッチ たとえばr化された単語とそうでない単語を一回で検索したい場合に使用する | 花|花儿 |
| [](ブラケット) | []は[]内の任意の 1文字にマッチする。範囲指定を使うこともできる。 この記号は日本語検索のほうがイメージしやすいので日本語の例をあげる [abcdef]は、 “a~f”のいずれか 1文字にマッチ [あいうえお]は、「あ~お」のいずれか 1文字にマッチ 走[らりるれろっ]は、「走る」のすべての活用形にマッチ もう 1つは、ハイフン(マイナスとも言う) ” -“による範囲指定である。”-“は文字クラス内では特殊な意味を持ち、[a-z]のように範囲指定することができる。 [あ-ん] ひらがな1文字にマッチ [0-9] 数字1文字にマッチ [A-Za-z] 英字1文字にマッチ [一-龠] 漢字1文字にマッチ ^を[]内の先頭で用いた場合、文字クラスの否定を表す。 [^0-9] は、数字以外の 1文字にマッチ [^A-Z] は、英字大文字以外の 1文字にマッチ | |
| ()(パーレン) | ()には 2つの意味がある。 1つは正規表現をグループ化するものである。 もう 1つの使い方は、後方参照 (backreference) とよばれるものである。 \1~\9で引用する部 分を指定する。数字は、 n番目の( )に対応することを示す。 (.)¥1 は、 AA、BB、看看、 多多…にマッチ (.+)¥1 は、看看、说明说明…にマッチ つまり、 上の正規表現の意味は、任意の 1文字をもう一度引用するということで、 2字の畳語にマッチし、 下の正規表現は、 1文字以上の文字列をもう一度引用することで、 AA、ABAB、 ABCABCのような文字列にマッチする。 | 李(先生|同志|师傅) (高兴)+ |
| {}(繰り返し) | {}は、ある一定回数以上の繰り返しを指定するためのメタキャラクタである。 {n} は、直前の1文字(または正規表現)の n回の繰り返しにマッチする。 {1,3} と記述する場合、直前の1文字(または正規表現)の1回から3回までの繰り返しにマッチする。 [0-9]{5}は 5桁の数字にマッチ a{1,3] は、 a、aa、aaaにマッチ {min, max} は、直前の 1文字(または正規表現)のmin回-max回の繰り返しにマッチする。 minの省略は 0回、 maxの省略は∞回(無限大)の指定と解釈される。 *、+、?、 {min,max} は、繰り返しパターンとして最大回数の繰り返しマッチを試みること になっているが、直後に?を追加することで最小回数の繰り返しでうち切ることができる。 「*?」直前の正規表現の0回以上の繰り返し(最小回数、つまり0回を優先的)にマッチ 「+?」直前の正規表現の1回以上の繰り返し(最小回数、つまり1回を優先的)にマッチ 「??」直前の正規表現の0回あるいは1回の繰り返し(最小回数、つまり0回を優先的)に マッチ {min,max}? 直前の正規表現のmin回? max回の繰り返し(最小回数)にマッチ |
離合詞の検索例
| 正規表現例 | 正規表現の意味 | マッチするもの |
| 结.婚 | 任意の 1文字が入る | 结了婚,结过婚,结完婚… |
| 结.?婚 | 0文字か任意の1文字が入る | 结婚,结了婚,结完婚… |
| 结..婚 | 任意の 2文字が入る | 结不起婚,结不了婚… |
| 结…婚 | 任意の 3文字が入る | 结了两次婚… |
| 结.*婚 | 0文字~任意の文字列 | 结婚,结过婚,结了一次根草率的婚… |
| 结.+婚 | 1文字~任意の文字列 | 结了婚,结过三,四次婚… |
不連続成分の検索
“因为…所以”‘”虽然…但是”‘”虽然…可是”‘”虽然…不过”のように、それぞれ単独でも使えるが、前後呼応して使用される不連続成分は、共起情況を調べるのに“因为.+所以”というように正規表現を用いる。
“是…的…”‘”ー…就…”のように呼応(搭配)してはじめて所定の形式的な意味を表すものは、“是.{5,8}的(。|,)”のように検索条件を指定すれば、“是”と“的”の間の文字数を 5~8に、“的”の直後に句読点が来るものに限定されることになる。“是.{4,8}的.+[,。?]“のように指定すれば、次のような目的語が“的”の後に置かれている用例も検出することができる。
他是昨天去的北京。
我说,‘‘前天不是我伯一起打的电报?”
- 量詞の”道”を抜き出すには? 例)[一|二|三|两]道
- 形容詞の”大”を抜き出すには? 例)[非常|很|特别]大
- 次の離合詞の使用頻度を調べてみましょう。
生气 请客 洗澡 上当 睡觉 撒谎 吃亏 帮忙 毕业 离婚 - 次のパターンはどうやったら言検索できるか正規表現を考えてみましょう。
又…又…/ー… 就… / オ…就… / 越…越… / 连…都(也)… / 既然…那么(就) … / 无论…(还是)…都(也) / 无论…(还是)…都(也) / 不管… (都)也… / 只有…オ… / 只要…就… / 即使…也… / 尽管…可是…
重ね型やパターンの検索
最後に、自分の研究対象のデータを探す方法を考えてみましょう。
- 大陸と台湾で使用される「語気助詞」を比較するには?→(Google限定検索など)
- 中国語の誤用の分析→(HSK动态作文语料库)
- 日中の小説の翻訳比較→(原文と翻訳文のデータ作成・収集とGrep検索)
- 文頭成分の構成に関する考察→(正規表現の$~検索、BCCコーパスで「。後ろ検索」)